|
|
|
| |
|
| |
Context-Based Adaptive Binary
Arithmetic
Coding (CABAC)
Overview
and Historical Perspective: The
algorithm of context-based
adaptive binary arithmetic coding (CABAC) has been
developed within the joint standardization activities of
ITU-T and ISO/IEC for the design and specification of H.264/AVC as the
latest member in
the family of international video coding standards. In a first
preliminary
version, the new entropy-coding method of CABAC was introduced as a
standard contribution [VCEG-L13] to the ITU-T VCEG meeting in January
2001. From that time until completion of the final standard
specification of H.264/AVC (Version 1) in May 2003, the CABAC algorithm
underwent a series of revisions and further refinements.
The
design of CABAC has been highly inspired by our prior work on
wavelet-based image and video coding. However, in comparison to these
studies, additional aspects previously largely ignored have been taken
into account during the development of CABAC. These aspects are mostly
related to implementation complexity and additional requirements in
terms of conformity and
applicability. As a consequence of these naturally
important criteria within any standardization effort, additional
constraints have been imposed on the design of CABAC with the result
that some of its original algorithmic components, like the binary
arithmetic coding engine have been completely re-designed. Other
components that are needed to alleviate potential losses in coding
efficiency when using small-sized slices, as further
described below, were added at a later stage of the
development. Support of additional coding tools such as interlaced
coding, variable-block size transforms (as considered
for Version 1 of H.264/AVC) as well as the later
re-introduced, simplified use of 8x8 transforms have also been
integrated at a time when the core design of CABAC was already reaching
a level of technical maturity.
At that time - and
also at a later stage when the scalable extension of H.264/AVC was
designed - another feature of CABAC has proven to be very useful. It
turned out that in contrast to entropy-coding schemes based on VLCs,
the CABAC coding approach offers an additional advantage in terms of
extensibility such that the support of newly added syntax elements can
be achieved in a more simple and fair manner. Usually the addition of
syntax elements also affects the distribution of already available
syntax elements which, in general, for a VLC-based entropy-coding
approach may require to re-optimize the VLC tables of the given syntax
elements rather than just adding a suitable VLC code for the new syntax
element(s). Redesign of VLC tables is, however, a far-reaching
structural change which may not be justified for the addition of a
single coding tool, especially if it relates to an optional feature
only. Since CABAC guarantees an inherent adaptivity to the actually
given (conditional) probability, there is no need for further
structural adjustments besides the choice of a binarization or context
model which, as a first approximation, can be chosen in a canonical way
by using the prototypes already specified in the CABAC design.
CABAC
has been adopted as a normative part of the H.264/AVC standard;
it is one of two alternative methods of entropy coding in the new video
coding standard. The other method specified in H.264/AVC is a
low-complexity entropy-coding technique based on the usage of
context-adaptively switched sets of variable-length codes, so-called Context-Adaptive
Variable-Length Coding
(CAVLC). Compared to CABAC, CAVLC
offers reduced implementation costs at the price of lower compression
efficiency. For TV signals in standard- or high-definition resolution,
CABAC
typically provides bit-rate savings of 10-20% relative to CAVLC at the
same objective video quality.
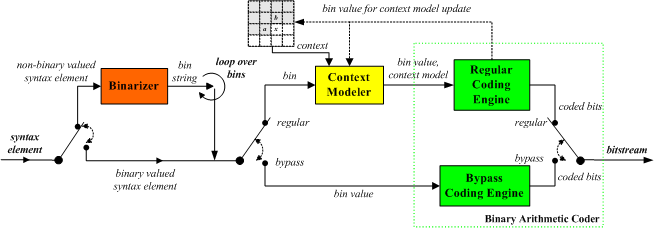 High-Level Summary of Algorithmic
Features: The
design of CABAC involves the key elements of binarization, context
modeling,
and binary
arithmetic
coding.
These elements are illustrated as the main
algorithmic building blocks of the CABAC encoding block diagram, as
shown above.
Binarization:
The coding strategy of CABAC is based on the finding that a very
efficient coding of syntax-element values in a hybrid block-based video
coder, like components of motion vector differences or
transform-coefficient level values, can be achieved by employing a
binarization scheme as a kind of preprocessing unit for the subsequent
stages of context modeling and binary arithmetic coding. In general, a
binarization scheme defines a unique mapping of syntax element values
to sequences of binary decisions, so-called bins,
which can also be interpreted in terms of a binary code tree. The
design of binarization schemes in CABAC is based on a few elementary
prototypes whose structure enables simple online calculation and which
are adapted to some suitable model-probability distributions.
Coding-Mode
Decision and Context Modeling: By decomposing each syntax
element value into a sequence of bins, further processing of each bin
value in CABAC depends on the associated coding-mode decision which can
be either chosen as the regular or the bypass
mode.
The latter is chosen for bins related to the sign information or
for lower significant bins which are assumed to be uniformly
distributed and for which, consequently, the whole regular binary
arithmetic encoding process is simply bypassed. In the regular coding
mode, each bin value is encoded by using the regular binary
arithmetic-coding engine, where the associated probability model is
either determined by a fixed choice, without any context modeling, or
adaptively chosen depending on the related context model. As an
important design decision, the latter case is generally applied to the
most frequently observed bins only, whereas the other, usually less
frequently observed bins, will be treated using a joint, typically
zero-order probability model. In this way, CABAC enables selective
context modeling on a sub-symbol level, and hence, provides an
efficient instrument for exploiting inter-symbol redundancies at
significantly reduced overall modeling or learning costs.
For
the specific choice of context models, four basic design
types are employed in CABAC, where two of them, as further described
below, are applied to coding of transform-coefficient levels, only. The
design of these four prototypes is based on
a
priori
knowledge about the typical characteristics of the source data to be
modeled
and it reflects the aim to find a good compromise between the
conflicting objectives of avoiding unnecessary modeling-cost overhead
and
exploiting the statistical dependencies to a large extent.
High-Level Summary of Algorithmic
Features: The
design of CABAC involves the key elements of binarization, context
modeling,
and binary
arithmetic
coding.
These elements are illustrated as the main
algorithmic building blocks of the CABAC encoding block diagram, as
shown above.
Binarization:
The coding strategy of CABAC is based on the finding that a very
efficient coding of syntax-element values in a hybrid block-based video
coder, like components of motion vector differences or
transform-coefficient level values, can be achieved by employing a
binarization scheme as a kind of preprocessing unit for the subsequent
stages of context modeling and binary arithmetic coding. In general, a
binarization scheme defines a unique mapping of syntax element values
to sequences of binary decisions, so-called bins,
which can also be interpreted in terms of a binary code tree. The
design of binarization schemes in CABAC is based on a few elementary
prototypes whose structure enables simple online calculation and which
are adapted to some suitable model-probability distributions.
Coding-Mode
Decision and Context Modeling: By decomposing each syntax
element value into a sequence of bins, further processing of each bin
value in CABAC depends on the associated coding-mode decision which can
be either chosen as the regular or the bypass
mode.
The latter is chosen for bins related to the sign information or
for lower significant bins which are assumed to be uniformly
distributed and for which, consequently, the whole regular binary
arithmetic encoding process is simply bypassed. In the regular coding
mode, each bin value is encoded by using the regular binary
arithmetic-coding engine, where the associated probability model is
either determined by a fixed choice, without any context modeling, or
adaptively chosen depending on the related context model. As an
important design decision, the latter case is generally applied to the
most frequently observed bins only, whereas the other, usually less
frequently observed bins, will be treated using a joint, typically
zero-order probability model. In this way, CABAC enables selective
context modeling on a sub-symbol level, and hence, provides an
efficient instrument for exploiting inter-symbol redundancies at
significantly reduced overall modeling or learning costs.
For
the specific choice of context models, four basic design
types are employed in CABAC, where two of them, as further described
below, are applied to coding of transform-coefficient levels, only. The
design of these four prototypes is based on
a
priori
knowledge about the typical characteristics of the source data to be
modeled
and it reflects the aim to find a good compromise between the
conflicting objectives of avoiding unnecessary modeling-cost overhead
and
exploiting the statistical dependencies to a large extent.
Pre-Coding
of Transform-Coefficient Levels: Coding of residual data
in CABAC involves specifically designed syntax elements that are
different from those used in the traditional run-length pre-coding
approach. For each block with at least one nonzero quantized transform
coefficient, a sequence of binary significance flags, indicating the
position of significant (i.e., nonzero) coefficient levels within the
scanning path, is produced in a first step. Interleaved with these
significance flags, a sequence of so-called last
flags (one for each significant coefficient level) is generated for
signaling the position of the last significant level within the
scanning path. This so-called significance information
is transmitted as a preamble of the regarded transform block followed
by the magnitude and sign information of nonzero levels in reverse
scanning order. The context-modeling specifications for coding of
binarized level magnitudes are based on the number of previously
transmitted level magnitudes greater or equal to 1 within the
reverse scanning path, which is motivated by the observation that
levels with magnitude equal to 1 are statistical dominant at
the end of the scanning path. For context-based coding of the
significance information, each significance / last flag is conditioned
on its position
within the scanning path which can be interpreted as a
frequency-dependent context modeling. Furthermore, for each of the
different transforms (16x16, 4x4 and 2x2) in H.264/AVC
(Version 1) as well as for luma and chroma component,
a different set of contexts denoted as context
category is
employed. This allows the discrimination of
statistically different sources with the result of a significantly
better adaptation to the individual statistical characteristics.
Probability
Estimation and Binary Arithmetic Coding: On the lowest
level of processing in CABAC, each bin value enters the binary
arithmetic encoder, either in regular or bypass coding mode. For the
latter, a fast branch of the coding engine with a considerably reduced
complexity is used while for the former coding mode, encoding of the
given bin value depends on the actual state of the associated adaptive
probability model that is passed along with the bin value to the M
coder - a
term that has been chosen for the
novel table-based binary arithmetic coding engine in CABAC. The
specific
features and the underlying design principles of the M coder can be
found here. In the
following, we will present some important aspects of
probability estimation in CABAC that are not intimately tied to the M
coder design.
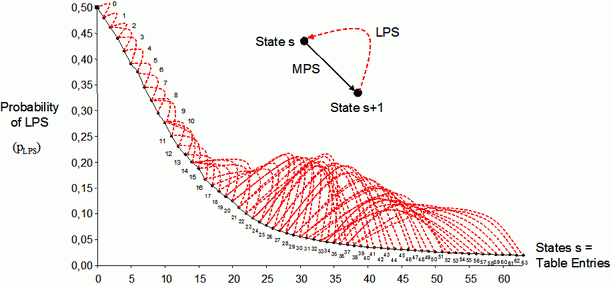
Probability
estimation in CABAC is based on a table-driven
estimator using a finite-state machine (FSM) approach with transition
rules as illustrated above. Each probability model in CABAC can
take one out of 128 different states with associated probability values
p
ranging
in the interval [0.01875, 0,98125]. Note that with the distinction
between the least probable symbol (LPS) and the most probable symbol
(MPS), it is sufficient to specify each state by means of the
corresponding LPS-related probability pLPS ∈
[0.01875, 0,5].
The method for designing the FSM transition rules was borrowed
from HOWARD and VITTER
using a model of "exponential aging" with the following transition rule
from time instance t to t+1:
| p(t+1)LPS = |
{
|
|
|
| if an
MPS occurs (black solid lines in graph above)
|
|
|
|
| if an
LPS occurs
(red dashed lines in graph above). |
|
|
|
According to this relationship, the scaling factor a can be determined by pmin = 0.5 αN-1,
with the choice of pmin
= 0.01875 and N = 128 / 2 = 64. Note however that the actual transition
rules, as tabulated in CABAC and as shown in the graph above, were
determined to be only approximately equal to those derived by this
exponential aging rule.
Typically, without any
prior knowledge of the statistical nature of the source, each model
would be initialized with the state corresponding to a uniform
distribution (p = 0.5).
However, in cases where the amount of data in the process of
adapting to the true underlying statistics is comparably small, it is
useful to
provide some more
appropriate initialization values for each probability model in order
to better reflect its typically skewed nature. This is the purpose of
the initialization process for context models in CABAC which operates
on two levels. On the lower level, there is the quantization-parameter
dependent initialization which is invoked at the beginning of each
slice. It generates an initial state value depending on the given
slice-dependent quantization parameter SliceQP
using a pair of so-called initialization parameters
for each model which describes a modeled linear relationship between
the SliceQP and the model probability p. As an
extension
of this low-level pre-adaptation of probability models, CABAC provides
two additional pairs of initialization parameters for each model that
is used in predictive (P) or bi-predictive (B) slices. Since the
encoder can choose between the corresponding three tables of
initialization parameters and signal its choice to the decoder, an
additional degree of pre-adaptation is achieved, especially in the case
of using small slices at low to medium bit rates.
Related overview paper:
D.
Marpe, H. Schwarz, and T. Wiegand: Context-Based
Adaptive Binary Arithmetic Coding in the H.264 / AVC Video Compression
Standard, IEEE Transactions on Circuits and Systems
for Video Technology, Vol. 13, No. 7, pp. 620-636, July 2003,
invited paper. [PDF]
Erratum: On p. 631, left column below
Table VI, "max(...)" must be replaced by
"min(...)" in the two
expressions for specifying context index increments for bins related to
absolute values of transform coefficients.
Related standard
contributions (in chronological order, as
listed here):
[VCEG-L13], [VCEG-M59], [VCEG-O18], [JVT-B100], [JVT-B101], [JVT-C060],
[JVT-C061], [JVT-D019], [JVT-D020], [JVT-D021],
[JVT-E059],
[JVT-E086], [JVT-E154], [JVT-F039]
Back
to Home Page Detlev Marpe
|
|
|

 Start
Start Staff
Staff